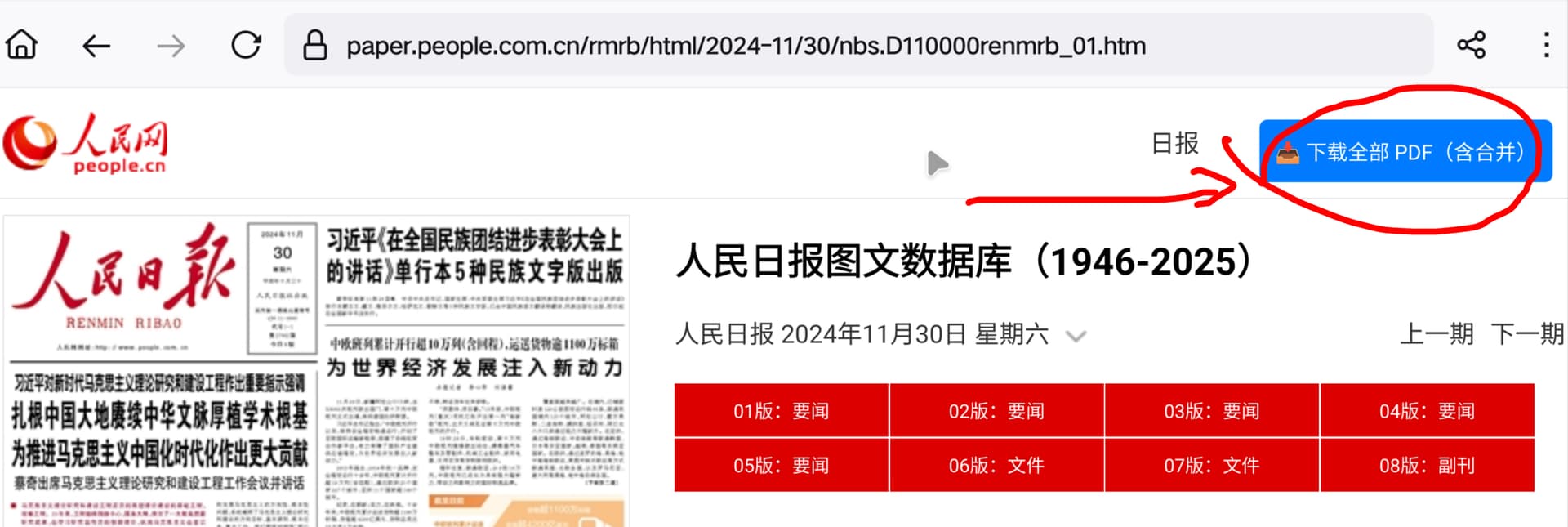
使用方法
安装插件,访问人民日报电子版网页,点击右上角的下载按钮,耐心等一会
代码
// ==UserScript==
// @name 人民日报 PDF 批量下载 + 合并
// @namespace http://blog.liyunhe.wang/
// @version 1.0
// @description 自动抓取人民日报当前日期所有版面 PDF 并可合并下载
// @author liyunhe && ChatGPT
// @match https://paper.people.com.cn/rmrb/html/*
// @match https://paper.people.com.cn/rmrb/pc/*
// @match http://paper.people.com.cn/rmrb/html/*
// @match http://paper.people.com.cn/rmrb/pc/*
// @grant none
// @require https://cdn.jsdelivr.net/npm/pdf-lib/dist/pdf-lib.min.js
// ==/UserScript==
(function() {
'use strict';
// 添加按钮
const btn = document.createElement('button');
btn.textContent = '📥 下载全部 PDF(含合并)';
btn.style = 'position:fixed;top:20px;right:20px;z-index:9999;padding:10px;background:#007bff;color:white;border:none;border-radius:5px;cursor:pointer;';
document.body.appendChild(btn);
btn.onclick = async () => {
btn.disabled = true;
btn.textContent = '⏳ 正在抓取数据...';
try {
const { date, detailedLinks } = await getPDFLinks(location.href);
const validLinks = detailedLinks.filter(link => link.pdfUrl);
if (validLinks.length === 0) {
alert('❌ 未找到任何 PDF 链接');
return;
}
const pdfBlobs = [];
for (let i = 0; i < validLinks.length; i++) {
const { title, pdfUrl } = validLinks[i];
btn.textContent = `⬇️ 下载中:${title} (${i + 1}/${validLinks.length})`;
const res = await fetch(pdfUrl);
const blob = await res.blob();
pdfBlobs.push({ title, blob });
}
btn.textContent = '📚 合并 PDF 中...';
const mergedBlob = await mergePDFs(pdfBlobs.map(p => p.blob));
const mergedFilename = `人民日报-${date}.pdf`;
triggerDownload(mergedBlob, mergedFilename);
btn.textContent = `✅ 下载完成:${mergedFilename}`;
} catch (err) {
console.error(err);
alert('❌ 出错:' + err.message);
} finally {
setTimeout(() => {
btn.disabled = false;
btn.textContent = '📥 下载全部 PDF(含合并)';
}, 5000);
}
};
// 抓取当前页面所有 PDF 链接
async function getPDFLinks(mainUrl) {
const res = await fetch(mainUrl);
const html = await res.text();
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
const dateMatch = doc.querySelector('.date')?.textContent.match(/(\d{4})年(\d{2})月(\d{2})日/);
const date = dateMatch ? `${dateMatch[1]}-${dateMatch[2]}-${dateMatch[3]}` : 'unknown';
const pageLinks = [...doc.querySelectorAll('#pageLink')]
.map(el => ({
title: el.textContent.trim(),
url: new URL(el.getAttribute('href'), mainUrl).href
}));
const detailedLinks = await Promise.all(pageLinks.map(async ({ title, url }) => {
try {
const res = await fetch(url);
const html = await res.text();
const subDoc = new DOMParser().parseFromString(html, 'text/html');
const href = subDoc.querySelector('.paper-bot a')?.getAttribute('href');
const pdfUrl = href ? new URL(href, mainUrl).href : null;
return { title, pdfUrl };
} catch {
return { title, pdfUrl: null };
}
}));
return { date, detailedLinks };
}
// 合并多个 PDF Blob
async function mergePDFs(blobs) {
const mergedPdf = await PDFLib.PDFDocument.create();
for (const blob of blobs) {
const arrayBuffer = await blob.arrayBuffer();
const pdf = await PDFLib.PDFDocument.load(arrayBuffer);
const pages = await mergedPdf.copyPages(pdf, pdf.getPageIndices());
pages.forEach(p => mergedPdf.addPage(p));
}
const mergedBytes = await mergedPdf.save();
return new Blob([mergedBytes], { type: 'application/pdf' });
}
// 触发浏览器下载
function triggerDownload(blob, filename) {
const a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = filename;
a.click();
URL.revokeObjectURL(a.href);
}
})();

已有 0 条评论